Clean Architecture in Frontend
A little theory and an open-source example

Writing about frontend development and other things that sparkle my interest
I wanted to share several insights that I found helpful for large-scale front-end applications. I want to talk about ideas that proved reliable in practice. At the same time, I pursue simplicity in my explanations.
I also implemented an uncomplicated To-Do List application to support the verbal explanation. The application uses the same design principles I apply on a much larger scale. I will use this application to give examples of individual components. You are also welcome to check out the source code on Github to examine the complete picture yourself.
The examples use Angular and tools around it. The general principles can be applied in any other ecosystem.
Screenshot of the final application. You can play with it here.
Clean Architecture
I'm inspired by Bob Martin's book, Clean Architecture. That's a great read with a lot of insights about software architecture in general. It's an excellent and well-structured overview of things that matter during system design. I found the ideas of Clean Architecture are applicable in frontend development too.
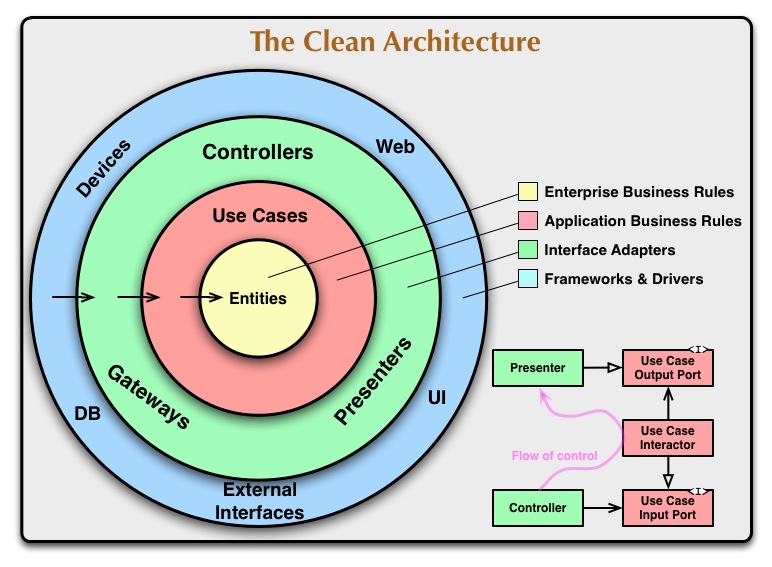 I found this diagram in the book and The Clean Code Blog.
I found this diagram in the book and The Clean Code Blog.
Clean Architecture is a way to isolate an application from frameworks, UI, and databases and ensure that individual components are testable. It leverages SOLID principles and shows how to put them together on a larger scale.
In this article, I'm describing just one way of Clean Architecture implementation. I use Angular as a framework and as a dependency injection container.
High-level frontend architecture
When I approach a new feature, I think about the underlying entity and the operations it needs. This diagram shows a high-level architecture of a new feature. Let's take a closer look at each of these layers.
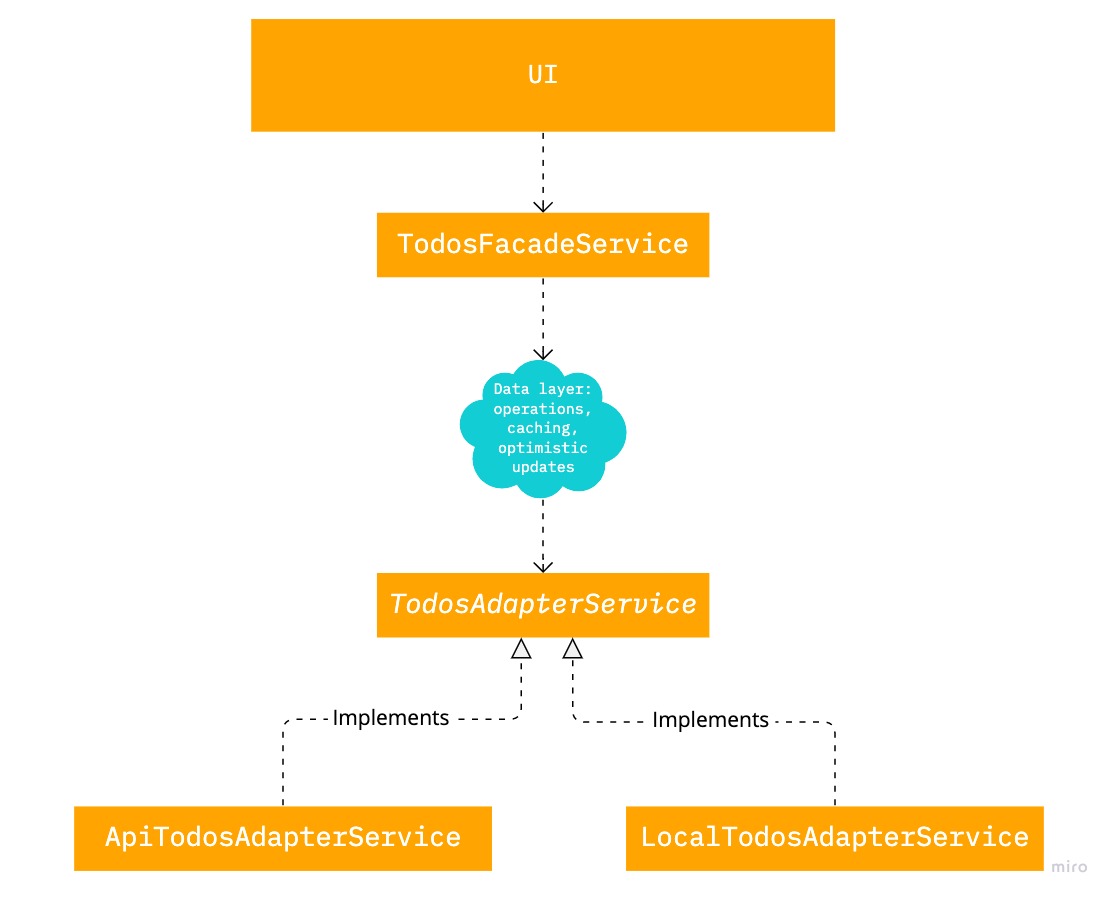
Entity
The application layers have a hierarchy. Entities are on the top, and UI is on the bottom. A layer must not have a dependency on any other underlying layer. For example, the entity should know nothing about the UI. As trivial as it sounds, Entity is probably the most crucial part of clean architecture. That's where I start designing completely new features. This part I protect from the changes the most. Although it's not on the diagram, the Entity flows between all these layers.
Looks simple enough, right? Yes, an entity can be as simple as a Typescript interface. The core idea is to include only those properties that describe the domain of a new feature. Any state that can be derived from these properties doesn't belong here.
One of the typical mistakes is putting to the entity additional information that helps with rendering. Any time you modify the entity, you must double-check that the new data belongs to the domain. This information must be relevant regardless of the UI, data management framework, or API.
Data layer
The role of this layer is to provide a toolchain for the entity. What operations do you need? What are the boundary conditions before/after the operation is done? How often adapter (API) is called? Do you need optimistic updates? What about sorting, filtering, and pagination? Perhaps, you also need to search? And you probably need some specialized operations like done/undone for a to-do element.
There are many possibilities but make sure not to over-engineer your application. The business must require certain features before you implement the new operations to the data layer. Otherwise, the application might become too complex without a proper reason. In other words, why implement a feature if nobody needs it? Less code means less maintenance and faster implementation of new requirements.
The rest of the application depends on the logic in the data layer. It decides if UI receives an object from a cache or the remote API.
You can implement the data layer with any library or pattern you find appropriate for your application. It depends on how complex the app must be according to the business requirements. Some possibilities:
- Class with internal state. It might employ RxJs Subjects/Observables.
- Any Redux-inspired library. In this case, Facade will trigger actions instead of calling the data layer's methods directly.
- Any other state-management library.
- Facade can call the Adapter directly. Essentially it ignores the data layer if you don't need any caching logic.
Adapter
Strictly speaking, the Adapter belongs to the data layer too. That's a powerful concept to ensure that the application is well-isolated from the API and its potential changes. Data services depend on the adapter's abstraction that we fully control. It is an implementation of the dependency inversion principle: I create an abstract class for the adapter and then use it in the data services. I also write an adapter implementation that is entirely hidden from the rest of the application. As a result, the data layer dictates its technical requirements for the adapter implementations. Even though data flows from the adapter implementation to the data services, the adapter still depends on the data layer, not the other way around.
You can design your application in a way that the entire API interaction is fully isolated from the logic of your application. A couple of my favorite benefits:
- If the API changes, then all I have to do is to adjust adapter implementation.
- If the API isn't available, I can implement my application nevertheless. And after API is available, I still have to adjust only the adapter implementation.
In this application, I went with a localStorage-based implementation of the persistence layer. Later it can be easily replaced with API calls. This pattern saved me countless hours in my practice.
Facade
In today's example, a facade is an object that acts as an interface between UI and the data layer. Whenever UI needs to load todos or create a new one, it calls one of the facade methods and receives a result as an observable.
The facade, on the other hand, can be anything inside.
- In simple scenarios, I directly call methods of adapters if I don't need any caching or data management.
- In other cases I might trigger a redux-like action, e.g.
dispatch(loadTodos())and then listen for subsequentloadTodosSuccessandloadTodosFailureactions. - I can also pass the call from the facade to another service that orchestrates the interaction with adapters. It might be a self-written service based on RxJS Subjects or a third-party service like the ones from @ngrx/data (not to confuse with bare NgRx)!
I distributed responsibility over different classes. Data service is supposed to request data from the adapter, save data to the repository and orchestrate optimistic updates if needed. Data service defines how to alter the state after each operation.
Facade, on the other hand, exposes data API to the UI. It can request the list of to-dos or create a new one and then receive the response from the unified todos$ observable that hides all the responses' complexity. At the same time, you can notice that I use subscribe() inside the facade method and then return an observable itself.
I made such a decision for the convenience of application logic. Sometimes components that trigger an operation and the ones that receive the result are different. They also have different lifecycles. In this to-do application sometimes a trigger component is destroyed right after it requests some data, so I need to ensure that something else will receive the result and keep at least one subscription active. Facade conveniently feels this gap by introducing mandatory subscribe() inside. In addition, it ensures that the underlying data service doesn't have extra logic that is relevant only to the data consumers.
UI
Why, UI has logic too! It's a different one though. The UI talks exclusively to the facade. The job of the UI is to call facade at the right time, e.g. initialization of a component or some specific user action. In addition, UI is responsible for managing its state. Not all the state goes to the data layer. UI-layer must operate the UI-specific state.
There are many approaches to dealing with UI state. And again, the choice depends on the business requirements. Sometimes it's acceptable to store state simply in a component. In other cases, there should be a way to exchange data between UI components. I won't cover this topic today, and it might be a conversation for another day.
Putting everything together
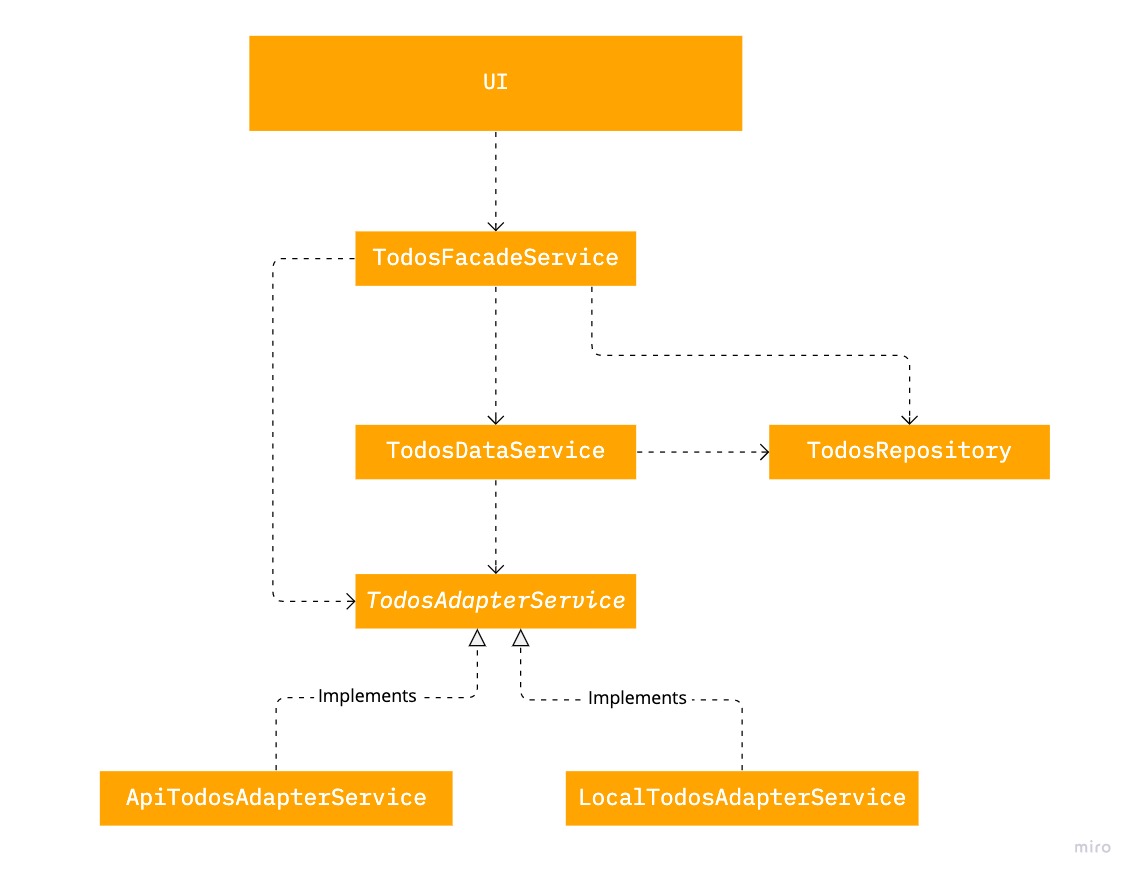
The data layer consists of the data service and the repository. Data service orchestrates operations and logic while the repository is responsible for in-memory caching. I use @ngneat/elf for the repository implementation. Although it can be any other library or even fully custom code.
The data service interacts with the abstract adapter to fetch the data. For the sake of simplicity, I scrapped the backend altogether and used a local-storage-based implementation. Remember, when the backend is available, the adjustments in our frontend application will likely be trivial.
What's next?
I intentionally pasted only part of the code in the article to illustrate the ideas. I encourage you to browse the source code and see everything yourself.
Would you like to read more on this topic? Perhaps, something else? Would you like to contact me? Feel free to leave a comment or find my contact on my personal page.
Attributions
The cover image: Crystal of copper sulfate. CC 4.0 Wikimedia Commons
